Comparing IPFS and BitTorrent in 2023.
We’re going to compare two of the largest P2P file-sharing networks! IPFS and ye olde BitTorrent. This research piece is based on a lot of experience I have with IPFS, namely integrating it into Dappnet.
This article is a work-in-progress. My goal is to collect a lot of data (50+ links so far) and simplified explanations that cut through a lot of the obtuse technical gala. This post isn’t intended to be a complete review of either project, DYOR. If you have any questions or if I’ve gotten anything wrong here, please reach out on Twitter @liamzebedee and I’d be happy to chat.
To begin with, since a lot of people don’t actually know how they work, I’m going to cover a little bit about their technical designs, and then we’ll go into their practical differences.
Table of contents:
- How does BitTorrent work?
- How does IPFS work?
- Similarities.
- Differences.
How does BitTorrent work?
BitTorrent was invented in 2001 by Bram Cohen, and you can find the original source code archive here.
BitTorrent allows you to share files faster, by downloading from multiple nodes serving the file. The way this works, is you divide the file into equal-sized pieces, and then you publish a torrent - which describes the hash of each individual piece. When you start the torrent client, it discovers peers and begins synchronising which pieces of a file that they have. When they find peers which have pieces they need, they request those pieces and then verify the integrity of them using the hash inside the torrent file.
The BT terminology usually refers to nodes that are sharing a file as seeders, and nodes that are downloading the file as leechers. Both seeders and leechers form the swarm, which is all the nodes serving a single torrent. The ratio of your upload to download is called a seed ratio. Good seed ratios get you faster download speeds, due to a protocol incentive design called tit-for-tat.
How do we find peers for a torrent? Peer discovery happens via two sources - trackers and the DHT.
- Trackers are centralized web servers which track peers for each torrent. They are very simple - the torrent file can specify a list of tracker URL’s, for example
udp://tracker.opentrackr.org:1337/announce, wherein the torrent client will “announce” itself to the tracker. It will then request a list of peers for the torrent and begin sharing data. - The DHT is a decentralized alternative to trackers - a DHT is a distributed hash table, meaning it is a distributed data structure which stores a mapping from keys to values. Specifically, the BitTorrent DHT called Mainline stores a
torrent -> (peer-list)mapping. It has over 1M nodes, and generally can resolve values in under 1s.
BitTorrent has a variety of clients and implementations, mostly reusing the C library libtorrent. BitTorrent works in browsers thanks to the webtorrent protocol, which defines a new substrate of BitTorrent running over WebRTC connections.
BitTorrent supports “mutable” torrents, whose content can be updated. BEP-44 introduced changes to the BitTorrent DHT where nodes could store arbitrary data under their public key. e.g. put(key=pubkey, value=anything), where the writes are authenticated via signatures. These values can only store 1000 bytes. Entries expire after 1h, and nodes must periodically re-announce them for replication by replaying the put message. BEP-46 built atop BEP-44 and introduced a magnet URI scheme for mutable torrents. A mutable torrent is subscribed to on the basis of a publisher’s public key.
How does IPFS work?
IPFS was invented in 2014 by Juan Benet, you can read the whitepaper here and technical documentation.
It’s a bit different to the torrent, in that all files exist in a global index that anyone can publish to. It’s like one big share drive.
There are generally two classes of IPFS nodes - those that are public resources, where you can publish files and it will host them for free (Cloudflare runs a node for example) - and nodes that only host content they are interested in, which is referred to as “pinning”.
IPFS nodes participate in sharing a global index which maps the load balancing unit of IPFS (blocks) to a list of peers which store this block. The index is distributed across a Kademlia DHT, where each (block -> peers) mapping is replicated on the closest 10 peers. The “closeness” proximity metric is the XOR function of Kademlia - ie. the dist(content, peer) = content_hash XOR peer_id - so generally speaking content is distributed uniformly across the peers.
Because the index is hosted on a laissz-faire basis, IPFS requires that nodes republish the content ID’s that they are hosting every 24h to the peers. This is quite network-intensive.
Like BitTorrent, each file is split into chunks called blocks. Each block is identified by its hash, called a CID (content ID). Unlike BitTorrent, the design does not stop at the notion of a single set of files. All of the files in IPFS are part of a larger data structure, the merkle DAG. The terms might make this hard to understand - the basic gist is that it’s like a typical file system (eg. ext4, NTFS, FAT32) but the data structure itself is merklized, and distributed over a Kademlia-like DHT. See IPLD for more.
Because everything compiles down to these blocks, in general, IPFS is more efficient when it comes to replicated data. In BitTorrent v1, changing one file in a torrent results in a completely different torrent infohash and thus requires a new swarm of peers to track it - whereas in IPFS, those existing files with the same hashes are hosted in the same peer set.
IPFS also features a “mutable file system” in the form of IPNS. IPNS allows you to publish content to a specific keypair, which can be updated. For example, you can publish a website, share the IPFS link https://cloudflare-ipfs.com/ipns/1Dk12123..., and later change some of that content and republish without changing the link. The way this works is that your “IPNS name” is the hash of your public key used for publishing. This is equivalant to mutable torrents in BitTorrent v2.
Some things of note:
- a great CLI -
ipfs add -R dir/ - simpler naming schemes:
/ipfs/Qm12123for content,/ipns/1Dk12123for “mutable content” - strong multiplatform support - js-ipfs (browsers), go-ipfs (desktops)
- standard HTTP gateway - meaning you can access IPFS content in your browser.
- fantastic primitives in the form of the libp2p networking stack, which are used by many other projects - such as Ethereum, my old work Keep Network, new startups like Renegade. libp2p is a seminal contribution to the P2P networking stack, bringing simple primitives for encrypted P2P communication, with NAT traversal built-in, and a slew of other useful features.
-
forward-facing data structures. e.g. multiformats, wherein the content ID describes the hashing algorithm it uses. This appears useful, but in practice is very hairy. Take for example this case in ENS domains.
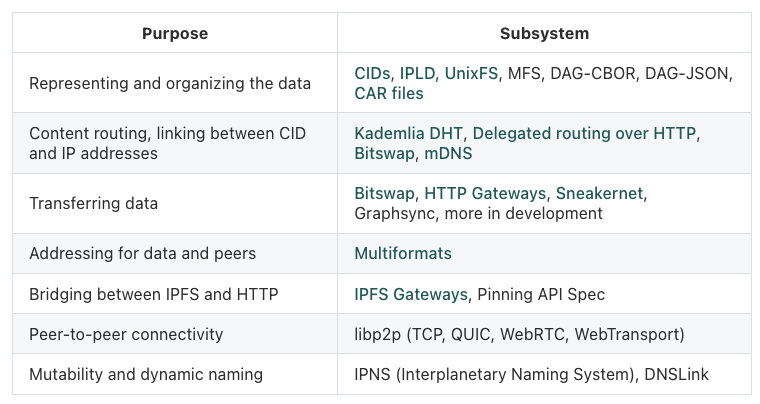
This table from their docs really exemplifies their engineering:
Filecoin.
It would be unfair to review IPFS without touching on the context of its development - Filecoin.
Filecoin is a product which lets you buy hosting services for IPFS content using a cryptocurrency, $FILE.
Filecoin works by building a “storage market” for data. This market is not an automatic market like Uniswap, rather it requires that nodes post storage “deals” which closely resembles an orderbook model. Filecoin nodes then store the data they are paid for, and this storage is audited by two mechanisms - proof-of-storage and proof-of-retrieval. I don’t know enough to give an accurate explanation here, you can read the whitepaper for more. The general gist is that storage providers are routinely tested that they are storing data, wherein random sampling of specific chunks occurs, and they post a ZK-SNARK proof that they custody that data (why ZK-SNARK’s? presumably because this is more efficient, space-wise).
Similarities.
A lexicon:
| BitTorrent | IPFS | |
|---|---|---|
| Nodes | Peers | Peers |
| Content | Pieces | Blocks |
| Infohash | CID (content ID) | |
| Torrent | CID (content ID) | |
| Data sharing model | Parallel downloads | Parallel downloads |
| Economic models | * Free - public torrent swarms * Paid - private trackers * Cryptonetworks - none. |
* Free - public IPFS nodes (Cloudflare). * Paid - paid IPFS pinning services (Pinata). * Cryptonetworks - Filecoin. |
| Actions | Seeding | Pinning |
| HTTP gateways | No | Yes |
| URI schemes | magnet: |
/ipfs/Qm..., /ipns/1Dk... |
Multiaddresses (/ip4/127.0.0.1/tcp/49852/p2p/16Uiu2HA...) |
||
| Networking | UDP, TCP, WebRTC | TCP, WebRTC |
| Types of content | Files and folders | Files and folders, larger data structures like blockchains (IPLD) |
| Peer discovery | Centralized trackers, DHT | DHT |
| Mutable content | torrent v2 (mutable torrents) | IPNS |
Differences.
- Intended use cases:
- BitTorrent is built for file-sharing.
- IPFS is built as a global P2P file system. It’s inspired by P2P approaches like the Coral CDN.
- Economic models.
- BitTorrent is a network of fiefdoms - store what you’re interested in, and only that. See private BitTorrent communities.
- IPFS resembles a public commons - like a CDN.
- Filecoin is an actual market - pay for storage.
- Relative context of the projects:
- BitTorrent is 20+ yrs old (started 2001), IPFS is only 5yrs old (started 2015).
- IPFS is funded by the Filecoin ICO, whereas BitTorrent is pure open-source, designed by its users.
- IPFS is quantitatively slower.
- There is lots of anecdotal evidence to support this, e.g. my users on Dappnet, the developers of the iroh node saying “on the order of seconds to resolve DHT queries”.
- BitTorrent peer discovery runs over UDP, IPFS runs over TCP. Theoretically, BT finds peers much quicker due to the overhead in TCP handshaking + libp2p encryption.
- IPFS is roughly 3x slower than BitTorrent, based on data in these two studies (1, 2):
The content retrieval process across all regions takes 2.90 s, 4.34 s, and 4.74 s in the 50th, 90th, and 95th percentiles
uTorrent’s DHT implementation takes 800 ms, 1.3 s, 1.5 s in the 50th, 90th, and 95th percentiles
- Broadly-speaking, IPFS exhibits a federated network architecture, whereas BitTorrent is more maximally decentralized.
- An IPFS node is largely more intensive in every way by default: storage - storing anyone’s data, networking - much higher gossip overhead for keeping data live in the DHT, CPU - anecdotally, higher CPU because of the above
- BitTorrent nodes by comparison, are extremely lightweight.
- IPFS-in-practice is developing more centralized solutions to this problem, like IPFS Network Indexers (IPNI).
- Both are on the spectrum of decentralization - neither are client-server architectures. BT is to the far right end of decentralization, whereas IPFS is closer towards the middle.
- IPFS’s core design is much cleaner than BitTorrent’s.
- A global namespace for files, where independent IPFS content can reuse content from other IPFS folders, is quite easy-to-use. This compares against BitTorrent’s mutable torrents.
- Mutable file-sharing is as simple as
ipfs add -r dir. - The IPFS gateway standard is ubiquitous. IPFS gateways have been deployed around the world, where you can access P2P content in browser (such as Cloudflare’s gateway, via .eth domains using eth.limo, etc.).
- Censorship and availability.
- One of the interesting differences is in censorship and availability.
- In IPFS, you are providing a chunk of your storage to everyone for free (the commons).
- In BT, you are only seeding the content you are interested in. For this reason, there are private communities which host movies and other things (private trackers) which thrive.
- IPFS’s design is more of a public share drive - you can publish images which will be hosted by Cloudflare, for free! And likewise, the IPFS protocol generally leaves it open to operators on how much content they host (pin).
- In practice, IPFS content gets banned from certain nodes and gateways. e.g. Tornado Cash censored from Cloudflare’s IPFS gateway.
- The general standard which has emerged in this ecosystem is the “bad bits denylist”, a curated list of CID’s which have been flagged for various reasons. The terminology here is quite an interesting choice - “We use the term “bad bits” when discussing topics involving copyright violations, DMCA, GDPR, Code of Conduct, or malware. This is a tactic to facilitate fruitful public discussion of concepts of freedom, censorship, privacy, and safety without slipping into destructive discussion patterns”.
- In practice, there is higher operational expense to running an IPFS gateway for the public - e.g. Publishers Carpet-Bomb IPFS Gateway Operators With DMCA Notices.
- Implementation-wise:
- BT is proven for large files - see the 700 Gb LLaMA dataset which was recently shared around the world.
- In practice, IPFS still has glaring pain points:
-
[1] - the IPFS protocol is hugely resource-intensive. Take this example of SciHub, which uses IPFS to distribute academic papers. Each paper is one IPFS CID, so for 1M papers, this involves 1M republications of “we are hosting this content” per 24h. The network gossip is quite intense - the IPFS protocol specifies gossipping the CID to the 20 closest peers, which in practice, due to the uniform distribution of these hashes, means gossipping to every known peer.
Picture this: 3 million books, at least one CID each (in practice it’s often multiple, since the libgen collection uses a chunk size of 256kb). Section 3.1 of the paper talks about content publication - for each CID, a provider record is published on up to 20 different peers. Because the CIDs are derived from a high-quality hash function, they are evenly distributed. So this means that a node with a sufficient number of items ends up connecting to every single node on the network. For 3 million CIDs * 20 publication records, this means sending out 60 million publication records, every 12 hours, i.e. an average of 1388 publication records per second (assuming one CID per file, which is conservative). This is just to announce to the network “hi… just wanted to let you know I still have the same content I did yesterday”. And every full replica of libgen is doing this.
-
[2] - some features of IPFS clients are still relatively immature, and not being improved with any priority. For example, the mutable file system (MFS) has a major performance regression according to this GH issue, when adding large numbers of files.
The changes to the MFS are crunching to a hold after a lot of consecutive operations, where single ipfs files cp /ipfs/$CID /path/to/file commands take 1-2 minutes while the IPFS daemon is taking 4-6 cores worth of CPU power.
I have this same issue. I’m maintaining a package mirror with approximately 400,000 files. ipfs files cp gets progressively slower as files are added to MFS.
-
- One team who was building an alternate high-performance IPFS implementation, iroh, has since broken rank and moved in a new direction for many of these same reasons.
- Markets and distribution.
- BitTorrent: ~3% of global internet traffic
- IPFS: supported by Cloudflare, a large corporate ecosystem of “IPFS pinning services” like Pinata
- Overall, BitTorrent feels like it is built in the philosophy of worse is better.